



Analiza procesowa, a obiektowa czyli niedopasowanie oporu
Tradycyjnie idziemy do WIKI:Tak właśnie jest: analiza obiektowa i modelowanie obiektowe to nie programowanie. Programowanie (wraz z projektowaniem elementów czysto technicznych) to implementacja modelu.
Przepraszamy, ale nie ma jeszcze artykułu „Analiza procesowa” w Wikipedii. (24 Maj 2011)
No cóż, szukamy dalej:
Process analysis presents a chronological sequence of steps that explain how something is done, how something happens, or how readers can do something. (źr. http://www.tcc.edu/students/resources/writcent/handouts/writing/process.htm).
Coś mamy: analiza procesowa prezentuje w postaci chronologicznej sekwencji kroków, to jak coś powstaje, co się wydarza lub jak można coś zrobić. Piękna definicja. Ta prezentacja to, w kontekście biznesowym, model (mapa) procesów biznesowych.
Mamy wiec uporządkowaną wiedzę o firmie (organizacji) zamawiającego oprogramowanie. Tu także powstaje opis tego po co i gdzie tego oprogramowania chcemy używać: model procesowy.
Tak zwane niedopasowanie oporu
Tak jest nazywana w literaturze różnica pomiędzy paradygmatem procesowym a obiektowym. Paradygmat procesowy operuje takimi pojęciami jak: proces, wejście procesu, wyjście procesu, zdarzenie, wykonawca procesu (zasoby), czynność (lub ich sekwencja). Paradygmat obiektowy to wspomniane obiekty czyli struktury łączące dane i metody ich przetwarzania. W czym problem? W przejściu z modelu procesowego na obiektowy. Czy to łatwe? Nie. Jak to zrobić? Hm… usiąść i popracować nad tym.
Należy przeprowadzić analizę obiektową i wykonać model obiektowy. Czego? Kodu? Nie! Organizacji zamawiającego!
Jak można radzić sobie z tym „niedopasowaniem”. Pomagają w tym zasady SOLID (w szczególności zasada otwartości na rozszerzenia i zamknięcia na modyfikacje oraz projektowanie zorientowane na zobowiązania klas) oraz wzorce DDD w analizie i projektowaniu.
To co tu opiszę nie jest „prostym algorytmem modelowania”, z pracy myślowej nikogo tu nie zwolnię. Moim celem jest uzupełnienie artykułu o szachownicy i artykułu o zbyt Niskim poziomie analizy o wskazanie, że model dziedziny jest bardziej elementem analizy i modelowania biznesowego niż projektowania i implementacji. Model ten to jedno z kluczowych wymagań: system ma realizować logikę opisaną w modelu dziedziny.
Jeżeli uznamy, że można (taki) model dziedziny implementować to jego opracowanie to także projektowanie. Nadal uważam, że nie jest to robota dla programisty, bo na jakiej podstawie on miał by taki model opracować?
Jak wygląda więc praca analityka biznesowego zgodnie z modelem kompetencyjnym IIBA (IIBA competency model). Kluczowym elementem pracy Analityka Biznesowego (w konwencji IIBA) jest prowadzenie (analiza) wymagań od momentu określenia potrzeby biznesowej aż do implementacji uzyskania właściwego rozwiązania. Jednak uzyskanie to nie to samo co własnoręczne wykonanie. Znowu analogia do budownictwa: architekt na bazie biznesowych celów swojego klienta opracowuje nie tylko wizualizację budynku ale także jego konstrukcję, do takiego poziomu by developer miał jednoznacznie postawione wymagania, nie blokuje to jednak developerowi „realizacji” wszelkich poza-funkcjonalnych wymagań.
Więc po kolei, opracowujemy.
Model procesu biznesowego
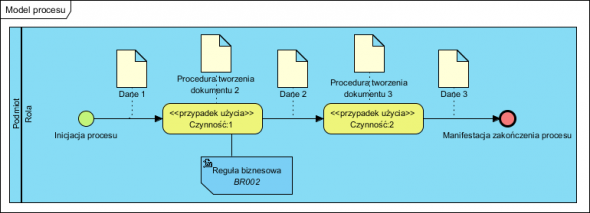
Czas zacząć analizować czyli projektować nasz System. Założenie: wymagane jest by System (oprogramowanie) wspierało oba procesy: 1 i 2 (przypomnę, że proces biznesowy to jedna czynność lub ich sekwencja, więc jedną czynność mającą wejście i wyjście także z definicji, utożsamiany z procesem biznesowym).
Usługi systemu
Usługi systemu to korzeń analizy obiektowej. Stanowią szkielet całego obiektowego projektu. tworzymy bardzo ważny diagram: diagram przypadków użycia.
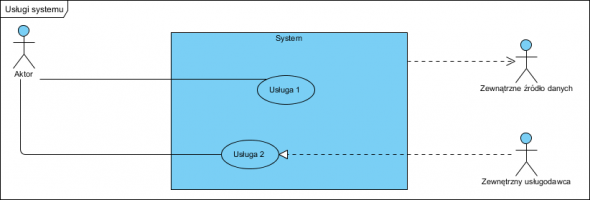
Często słyszę, że ten diagram nic nie wnosi do projektu. To nie prawda. Wnosi kluczową informację: wyznacza granice Systemu i wskazuje ewentualne powiązania z innymi systemami. Ale też nie prawdą jest, że służy do pokazania czegokolwiek ponad to, np. kolejności korzystania z usług czy struktury wewnętrznej. To ostatnie robimy w postaci modelu dziedziny.
Na powyższym diagramie udokumentowano:
- System oferuje użytkownikowi dwie usługi (to wymaganie by Czynność 1 i Czynność 2 procesu były wspierane przez System).
- System będzie korzystał z danych innego oprogramowania (Zewnętrznego źródła danych), wymagana jest więc integracja.
- Usługa 2 jest realizowana w całości przez inny, zewnętrzny system, wymagane jest od systemu więc by obsługiwał przekierowanie na inny system (np. realizacja płatności na stronie Banku).
Zakres projektu to wyłącznie to „co w środku”, albo lepiej: wszystko to co jest poza prostokątem System jest poza zakresem projektu. Nie dostarczamy ani Zewnętrznego źródła danych ani Systemu Zewnętrznego usługodawcy ale musimy na liście wymagań zapisać, że integracja z nimi jest wymagana i jaka ona ma być.
Logika działania Systemu – model dziedziny
Zabawa zaczyna się tu: zamieniamy „scenariusze” na „narzędzia i materiały”:
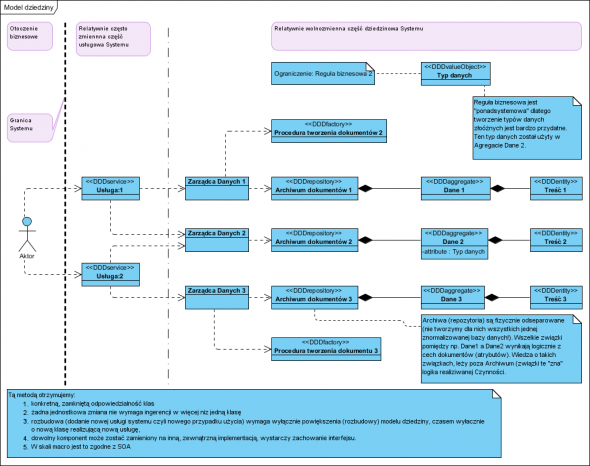
Celowo zachowałem nazwy tak by możliwe było „śladowanie” co z czego powstało. Kilka komentarzy, czyli dobre praktyki, wzorce i styl projektowania.
Każda usługa ma swoją dedykowaną klasę, zmiany realizacji jednej nie przeniosą się na inne. Usługi są więc od siebie niezależne. Oddzielono tworzenie dokumentów od ich przechowywania, dzięki czemu łatwo w przyszłości zmienić metody ich tworzenia bez potrzeby ingerencji w repozytorium. Wszelkie reguły biznesowe (w tym validacji) są „zamknięte” w tak zwanych złożonych typach danych (valueObject, sytuacja idealna to całkowity brak typów prostych (typy proste, primitives) w projekcie, wyłącznie typy złożone). W zasadzie zastąpienie wszystkich typów prostych na złożone w obszarze modelu dziedziny, otwiera w przyszłości drogę do ich rozbudowy bez potrzeby wprowadzania innych zmian w programie. Realnie pomiędzy Aktorem a usługą istnieją klasy widoku (GUI, View w MVC), tu nie umieszczone, bo klasy te nie realizują (nie powinny) żadnej logiki biznesowej.
Powyższy model:
Spełnia zasady SOLID (w szczególności System jest łatwy w rozszerzaniu i nie wymaga w tym celu zmian) Jest zgodny z DDD czyli struktura modelu odwzorowuje strukturę i pojęcia biznesowe.
Co zyskujemy? Niskie koszty dalszego rozwoju, łatwość wyceny projektu przez developera (zna architekturę). Powstanie takiego projektu daje mi gwarancję, że panuje nad nim. Owszem mogę założyć, że developer także taki model opracuje, jednak życie pokazuje, że prawie na pewno nie…
Powyższe z oczywistych powodów (mało miejsca i uogólnienie) nie zawiera szczegółów, ale te należy zawsze w projekcie odkładać na sam koniec. Dzięki temu możemy skupić się na rzeczach na prawdę ważnych (ważne jest by zrozumieć cel tworzenia dokumentu a nie spisać jego zawartość, ta ostatnia wynika z tego do czego służy).
Ostatni wpis na blogu, o Niskim poziomie analizy zawiera akapit:
Istnieje niestety także bardzo duże ryzyko, którego źródłem jest stosowanie starych, strukturalnych metod wytwarzania oprogramowania czyli „rozbiór” (i projekt) systemu na bazę danych i procedury. Ta praktyka (metoda) niestety daje jako efekt oprogramowanie bardzo kosztowne w projektowaniu i rozwoju. Od metod strukturalnych znacznie lepsze są metody obiektowe, niestety samo deklarowanie korzystania z .NET czy Java albo notacji UML nie czyni stosowanych metod obiektowymi.Właśnie dlatego analiza i wymagania powinny zawierać model dziedziny wraz z zaleceniami co do implementacji. Nie jest to dokument (ten model) dla sponsora projektu (w rozumieniu do czytania). Jego rola (wartość jaką wnosi do projektu) to minimalizacja ryzyka, że developer wykona coś czego nie chcemy.
A gdzie baza danych? Nie tu! Implementacja przechowywania danych to praca developera, nie wolno mu jedynie znormalizować powyższego modelu. Zaprojektowanie relacyjnego modelu i użycie mapowania obiektowo-relacyjnego zniszczy wszystkie zalety tego projektu a dodatkowo strasznie skomplikuje całość.
Na zakończenie, poniższy „potwór” (przykładów nie tylko w sieci, na pęczki) nie ma nic wspólnego z obiektowym paradygmatem, to typowy przykład strukturalnego (a nie obiektowego) projektowania w UML (użycie notacji UML bez błędów składni nie czyni tego projektu obiektowym, to bardzo zły projekt obiektowy, być może poprawny diagram UML):

Źródło: IT-Consulting
Autor: Jarosław Zieliński
